From Protocol Design to Data Lock. Without the Bottlenecks.
Trialhelix automates study build, EDC configuration, and CDISC SDTM/ADaM deliverables for biotech CROs running Phase I and II trials.
Purpose-Built for Regulated Trial Data
From first eCRF to final CDISC dataset — one connected workflow, four integrated capabilities.
Build study forms, visit schedules, and edit checks aligned to your DMP. Auto-configured from protocol without manual spreadsheet mapping.
Explore EDCStratified randomization and IRT integration built directly into the study build workflow. Supports Phase I escalation and Phase II arms.
Explore RandomizationAutomated MedDRA and WHO Drug coding, query generation, and dataset reconciliation. No SAS programmer required for SDTM mapping.
Explore Data ManagementTables, Listings, and Figures delivered from locked datasets. Pinnacle 21 validation built in. Submission-ready SDTM and ADaM packages.
Explore TLF Reporting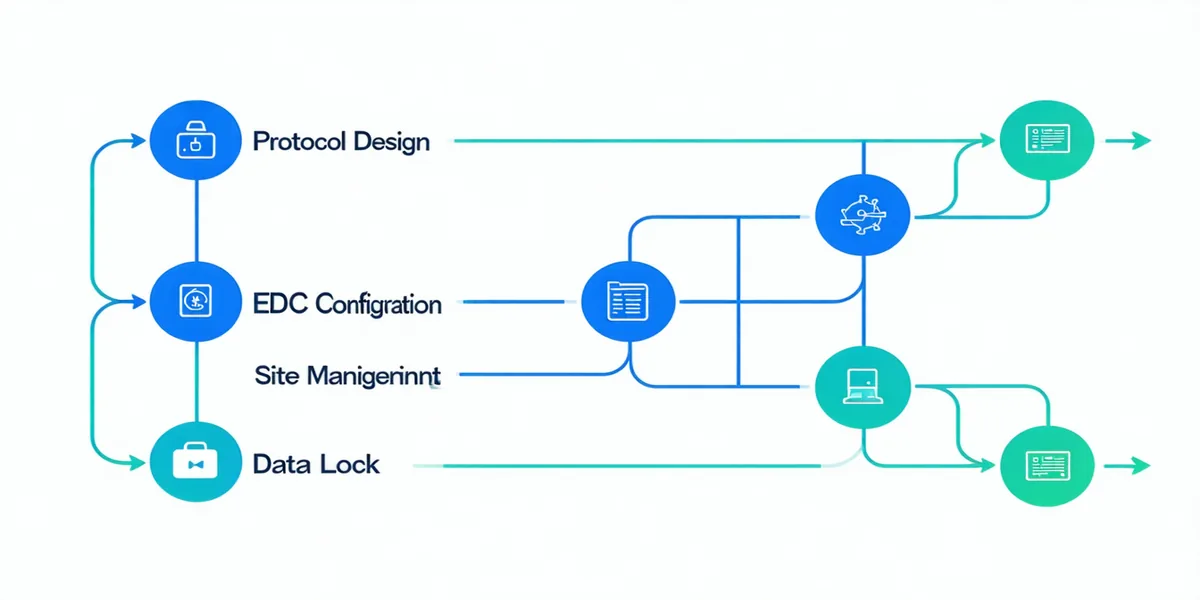
The Clinical Study Workflow, Step by Step
From protocol design through data lock — each step designed around ICH-GCP operational reality.
DMP, visit schedule, and eCRF specifications ingested
Forms, edit checks, and visit matrix built automatically
Site monitoring, SDV, and query management in one pipeline
Lock cycle with approval chain and reconciliation checklist
SDTM/ADaM datasets and TLF package, Pinnacle 21 validated
Built for the CRO Team That Actually Does the Work
Manual EDC configuration, query backlogs, and CDISC mapping overhead. These are the three biggest time sinks in Phase I and II data management — and Trialhelix is designed to eliminate each one.
Protocol-driven EDC configuration replaces weeks of manual spreadsheet mapping and UAT cycles.
Edit checks run continuously against incoming data. Query cycle time reduces by approximately 60% vs. manual workflows.
eCRF fields map automatically to SDTM domains. 22+ datasets generated from locked data. Pinnacle 21 validation included.

Designed With Regulatory Controls in Mind
Every workflow in Trialhelix is designed with the ICH-GCP and 21 CFR Part 11 framework as the reference — not as an afterthought.
Every field-level edit logged with user, timestamp, and reason for change. Designed to align with 21 CFR Part 11 electronic records requirements.
Protocol version control, IRB/IEC submission tracking, and site activation procedures built into study setup.
End-to-end encryption for all data movement. Role-based access controls with investigator, CDA, DM, and sponsor view layers.
What CRO Teams Are Saying
Study build used to take three weeks of manual EDC configuration. With Trialhelix, we completed the same build in four days and the CDISC mapping was already done.
We did not have to hire an SAS programmer for our SDTM package. Trialhelix generated the datasets, we ran Pinnacle 21, and the submission was ready.
From the Trialhelix Team
Technical guidance for clinical data managers, trial operations leads, and biotech sponsors navigating Phase I and II execution.

Automating CDISC SDTM: What Changes When the Mapping Happens at Study Build
Most SDTM mapping happens after data lock, as a separate exercise. When it happens at study build, the downstream impact on query cycle time and submission timelines is substantial.
Read article
EDC Query Cycle Time: Where the Days Go and How to Get Them Back
A Phase II trial's query backlog tells you everything about the EDC configuration decisions made at study build. Here is how to read it and fix it upstream.
Read article
Data Lock Best Practices for Phase I Studies: A Step-by-Step Reconciliation Guide
Data lock is not a single event — it is a process that begins at study design. The CROs that close fastest are the ones that treat reconciliation as a continuous activity.
Read articleReady to Cut Your Study Build Time in Half?
Trialhelix works with your existing DMP and protocol documentation. A technical call takes 30 minutes. We can walk through your specific study design and show you where automation applies.